Спаннер
Спаннер: Глобально-распределенная база данных Google
Abstract
Spanner - это распределенная, масштабируемая, мультиверсионная и синхронно-реплицируемая база данных. Это первая система, которая хранит данные распределенно в мировом масштабе и поддерживает распределенные транзакции с внешней консистентностью. Эта статья описывает структуру Spanner его функциональность, предпосылки и рассуждения для принятия каждого решения при разработке дизайна, новое API для синхронизации времени, которое позволяет преодолеть неопределенности во времени. Это API и его имплементация являются критическими для поддержки внешней консистентности и набора мощных функций: неблокирующие чтения, read-only транзакции без блокировок и атомарные изменения схемы в рамках всего Spanner.
1 Введение
Spanner - это масштабируемая, глобально-распределенная база даных, разработанная, построенная и внедренная в Google. На самом высоком уровне абстракции - это база данных, которая шардит данные между множеством наборов конечных автоматов Paxos[21] в датацентрах, расположенных по всему миру. Репликация используется для обеспечения глобальной доступности и географической локализованности; в случае отказа одного из них клиенты автоматически переключаются на другой. Спаннер автоматически решардит данные между машинами по мере того, как меняется объем даных или количество серверов, и автоматически мигрирует данные между машинами (даже между датацентрами) для того, чтобы балансировать нагрузку и в ответ на сбои. Спаннер разработан, для того, чтобы обеспечивать масштабируемость вплоть до миллиона машин между сотнями датацентров и триллионами кортежей данных.
Приложения могут использовать Спаннер благодаря доступности данных даже при природных катаклизмах, т.к. данные реплицируются в пределах и даже между континентами. Нашими первыми клиентами была система F1[35], переработанная версия рекламного бэкенда Google. F1 использует 5 реплик, распределенных в пределах США. Большинство других приложений, вероятно, реплицируют данные между 3-5 датацентрами внутри одной географической области, но с относительно независимыми режимами обработки сбоев. Таким образом, большинство приложений выберут низкую временную задержку (low latency) вместо доступности данных, так как они могут работать при одном или двух сбоях в датацентрах.
Главная цель Спаннера - управление реплицированными данными между датацентрами, но мы также уделили большое внимание дизайну и реализации важной функциональности на основе нашей распределенной инфраструктуры. Несмотря на то, что множество проектов успешно используют Bigtable[9], мы постоянно получаем жалобы от пользователей, что сложно использовать Bigtable для некоторых приложений: таких, которые имеют сложные, изменяющиеся схемы или те, которым необходима строгая консистентность при одновременной репликации в широких пределах. (Подобные жалобы высказывались многими авторами [37].) Множество приложений Google выбрали Megastore [5] из-за ее полу-реляционной модели данных и поддержки синхронной репликации, несмотря на относительно низкую скорость записи. Как результат, Спаннер развивился из похожего на Bigtable версионного хранилища key-value в хронологическую мультиверсионную базу данных. Данные хранятся в схематизированных полу-реляционных таблицах; данные имеют версию, и каждой версии автоматически присваивается время коммита; старые версии данных удаляются сборщиком мусора по конфигурируемым правилам; и приложения могут читать данные со старыми временными метками. Спаннер поддерживает транзакции общего назначения и поддерживает язык запросов на основе SQL.
Как глобально распределенная база данных, Спаннер предоставляет несколько интересных возможностей. Во-первых, конфигурации для репликации данных могут динамически и очень точно контролироваться приложениями. Приложения могут указывать, какие датацентры должны быть использованы для хранения конкретных данных, как далеко от пользователя могут данные находиться (для контроля задержки чтения), как далеко реплики находятся друг от друга (для контроля задержки записи) и как много реплик поддерживается (для контроля устойчивости, доступности данных и скорости чтения). Данные также могут динамически и прозрачно перемещаться системой между датацентрами для балансировки использования ресурсов между датацентрами. Во-вторых, Спаннер имеет 2 особенности, которые сложно реализовать в распределенной базе данных: он обеспечивает внешнюю консистентность [16] чтения и записи, и глобально-консистентные чтения в пределах всей базы данных для заданной временной метки (timestamp). Эти особенности позволяют Спаннеру поддерживать консистентные резервные копии, консистентное выполнение операций MapReduce [12] и атомарные изменения схемы, и все это на глобальном уровне, и даже при одновременном существовании незавершенных транзакций.
Эта функциональность обеспечивается тем фактом, что Спаннер присваивает временные метки коммита каждой транзакции, несмотря на то, что транзакции могут быть распределенными. Временные метки отражают порядок сериализации. В добавок, порядок сериализации удовлетворяет требованию внешней консистентности (или, что то же самое, линериализации [20]): если транзакция T1 завершается перед тем, как начинается другая транзакция T2, тогда временная метка для T1 меньше таковой для T2. Спаннер - это первая система, которая гарантирует это в глобальном масштабе.
Новое TrueTime API и его реализация - это та ключевая часть, которая позволяет реализовать все эти свойства. API напрямую выявляет временную неопределенность и требования, которые накладываются на временные метки, зависят от границ и ограничений реализации. Если неопределенность большая, то Спаннер замедляется, чтобы переждать её. Программное обеспечение для управления кластерами Google предоставляет реализацию TrueTime API. Эта реализация уменьшает временную неопределенность (обычно до 10 миллисекунд) путем использования множества временных источников (GPS и атомные часы).
Секция 2 описывает структуру Спаннера, набор функциональности, и инженерные решения, которые привели к такому дизайну. Секция 3 описывает наше новое TrueTime API и наборски его реализации. Секция 4 описывает, как Спаннер использует TrueTime для реализации внешне-консистентных распределенных транзакций, неблокирующих read-only транзакций и атомарных изменений схемы. В секции 5 - результаты бенчмарков производительности Спаннера и TrueTime и размышления насчет опыта использования F1. Секции 6, 7 и 8 описывают текущую и будущую работу и резюмируют наши заключения.
2 Реализация
Эта секция описывает структуру и размышления, лежащие в основе реализации Спаннера. Затем описывается абстракция директория, которая используется для управления репликацией и местом нахождения реплики, и является единицей перемещения данных. В конце секция описывает нашу модель данных, почему Спаннер выглядит как реляционная база данных, а не key-value хранилище, и как приложения могут контролировать место нахождения данных.
Инсталляция Спаннера называется вселенной. При условии, что Спаннер управляет данными на глобальном уровне, у нас будет только несколько функционирующих вселенных. На данный момент работает вселенная test/playground, вселенная development/production и только-production вселенная.
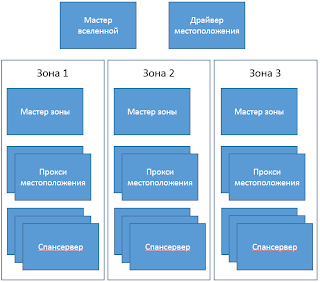
Спаннер организован как набор зон, где каждая зона является грубым аналогом инсталляции сервера Bigtable [9]. Зоны являются единицей административной инсталляции. Набор зон - это также и набор локаций в пределах которых данные могут быть реплицированы. Зоны могут быть добавлены или удалены из работающей системы подобно тому как новые датацентры вводятся в строй а старые отключаются соответственно. Зоны являются также единицей физической изоляции: может быть только одн или более зон в датацентре, например, если данные разных приложений могут быть распределены между различными наборами серверов в одном датацентре.
Рисунок 1 показывает сервера во вселенной. Зона имеет своего хозяина зоны и с количеством спансерверов от 100 до нескольких тысяч. Хозяин зоны передает данные спансерверам; последние уже передают их клиентам. По одному на каждую зону, прокси серверы локаций используются клиентами, чтобы определить местонахождение и сам спансервер, который должен отдать данные. Мастерспансервер.
вселенной и драйвер местоположения являются синглтонами. Мастер вселенной - это консоль, которая отображает текущую статусную информацию о всех зонах для интерактивной отладки. Драйвер местоположения автоматически перемещает данные между зонами меньше чем за одну минуту. Драйвер периодически общается со спан серверами, чтобы найти данные, которые необходимо переместить, для того, чтобы удовлетворить изменившимся ограничениям репликации или для балансировки нагрузки. Для экономии места, мы опишем в деталях только
2.1 Спансервер
Эта секция описывает реализацию спансервера, чтобы показать, как репликация и распределенные транзакции были поделены на слои на основе имплементации Bigtable. Набор программных компонент показан на рисунке 2. Внизу, каждый спансервер ответственен за структуры данных, называемые таблетами, количество которых находится в пределах от 100 до 1000 экземпляров. Таблет похож на абстракцию таблет в Bigtable, и реализует множество следующих соответствий:
(ключ: string, временная метка: int64) -> string
В отличие от Bigtable, Спаннер присваивает данным временную метку, которая делает Спаннер скорее мультиверсионной базой данных, нежели хранилищем key-value. Состояние таблета хранится в наборе файлов, похожих на B-дерево и в логе, все это в распределенной файловой системе, называемой Колоссом (последователем Google File System [15]).
Для поддержки репликации, каждый спансервер реализует одиночный конечный автомат Paxos поверх каждого таблета. (Ранние версии Спаннера поддерживали множество конечных автоматов Paxos для одного таблета, что давало возможность более гибко настраивать репликацию. Сложность этого дизайна заставила нас отказаться от этого.) Каждый конечный автомат хранит свои метаданные и логгирует их в соответствующем таблете. Наша реализация Paxos поддерживает долгоживущих лидеров со сроком жизни 10 секунд. Текущая реализация Спаннера сохраняет каждую запись в лог дважды: в лог таблета и в лог Paxos. Это - недостаток проектирования и он, вероятно, будет скоро исправлен. Наша реализация Paxos поддерживает конвейерные операции для того, чтобы улучшить пропускную способность Spanner при наличии задержек WAN: но транзакции записи, осуществляемые Paxos проходят в корректной последовательности (факт, от которого мы будем зависеть в Секции 4).
Конечный автомат Paxos используется для реализации постоянно реплицируемого множества соответствий. Множество key-value каждой реплики хранится в соответствующем таблете. Операции записи должны инициировать протокол Paxos на стороне лидера; чтение множества производятся напрямую из нижележащего таблета любой реплики, таблет выбирается самый актуальный. Набор реплик является группой Paxos.
У каждой реплики, которая является лидером, каждый спансервер реализует таблицу блокировок для управления параллелизмом. Таблица блокировок содержит состояние для двухфазной блокировки: она сопоставляет каждому интервалу ключей свое состояние блокировки. (Заметьте, что наличие долгоживущих лидеров Paxos является критическим фактором для эффективного управления таблицами блокировок). Как в Bigtable так и Спаннере, мы разрабатывали дизайн для долгоживущих транзакций (например, для создания отчетов, что могло занять несколько минут), которые имеют низкую производительность при оптимистичном контроле параллелизма (optimistic concurrency control) в присутствии конфликтов. Операции, которые требуют синхронизации, такие как транзакционные чтения запрашивают блокировку в таблице блокировок; другие - игнорируют таблицу.
В каждой реплике, которая является лидером, каждый спансервер использует транзакционный менеджер для поддержки распределенных транзакций. Транзакционный менеджер используется для реализации лидера-участника; другие реплики в группе называются ведомыми участниками. Если транзакция включает в себя только одну Paxos группу (также как и в случае большинства транзакций), она может не использовать менеджер транзакций, так как таблица блокировок и Paxos вместе обеспечивают транзакционность. Если в транзакцию вовлечены более чем одна группа Paxos, такие лидеры групп координируются и выполняют 2-х фазный коммит. Одна из групп-участников выбирается в качестве координатора: лидер участник этой группы будет называться координационным лидером, и ведомые будут соответственно называться координационными ведомыми. Состояние транзакционного менеджера хранится в нижележащих Paxos группах (и таким образом, реплицируется).
2.2 Директории и местоположение
На вершине всего набора отображений ключ-значение, реализация Спаннера поддерживает абстракцию корзин, называемую директорией, что есть непрерывный набор ключей, которые имеют общий префикс. (Понятие "директория" является исторической случайностью; "корзина" была бы более подходящим названием). Мы поясним источник этого префикса в секции 2.3. Поддержка директорий позволяет приложениям контролировать нахождение данных с помощью аккуратного выбора ключа.
Директория - это единица размещения данных. Все данные в директории имеют одну и ту же конфигурацию для репликации. Когда единица данных перемещаются между группами Paxos, то она перемещается директория за директорией, как это показано на рис. 3. Спаннер может перемещать директорию для планирования нагрузки из группы Paxos; чтобы расположить директории используемые вместе, в группу, которая ближе к своим пользователям. Директории могут быть перемещены во время выполнения клиентских операций. Можно ожидать, что 50 Мб директория может быть перемещена за несколько секунд.
Факт, что группа Paxaos может содержать несколько директорий предполагает, что таблет Спаннера отличается от таблета в Bigtable: первый не обязательно будет единственным лексикографически непрерывным разбиением в памяти. Наоборот - таблет в Спаннер является контейнером, который может выключать в себя множественные разбиения свободного пространства. Мы пришли к такому решению для того, чтобы сделать возможной систематизацию множества директорий, часто используемых вместе.
Movedir - это фоновая задача, которая используется для перемещения директорий между группами Paxos [14]. Movedir также используется для добавления и удаления реплик в группах Paxos [25], т.к. Спаннер еще не поддерживает изменения конфигурации внутри самого Paxos. Movedir реализован не как одна единственная транзакция, для того, чтобы избежать блокирования параллельно выполняющихся процессов чтения и записи во время перемещения. Вместо этого, movedir отмечает факт, что он начинает перемещать данные и перемещает данные в фоне. Когда он переместил все, за исключением последней маленькой части данных, он использует транзакцию, чтобы переместить эту малую часть атомарно и обновить метаданные для двух групп Paxos.
Директория также является минимальной единицей, чьи свойства репликации в зависимости от местоположения могут быть установлены приложением. Дизайн нашего языка спецификации местоположения позволяет разделить ответственность для управления конфигурациями репликации. Администраторы контролируют два измерения: количество и типы реплик и их географическое положение. Они создают меню именованных опций в этих двух измерениях (напр. Северная Америка, реплицируется по 5 путям с одним свидетелем). С помощью назначения комбинации этих параметров каждой базе данных приложение контролирует процесс репликации этих данных. Например, приложение может хранить данные каждого конечного пользователя в его собственной директории, что позволит данным пользователя A иметь 3 реплики в Европе, а данным пользователя B иметь 5 реплик в Северной Америке.
Для того, чтобы это было более понятно, мы всё сильно упростили. В действительности, Спаннер будет шардить директории на множество фрагментов, если директория станет слишком большой. Фрагменты могут быть отданы из разных групп Paxos (и таким образом, находящимися на разных серверах). Movedir на самом деле перемещает между группами фрагменты, а не целые директории.
2.3 Модель данных
Спаннер предоставляет приложениям следующий набор функций: модель данных, основанная на схематизированных пол-реляционных таблицах, язык запросов и транзакции общего назначения. Движение по направлению к поддержке этих функций поддерживалось многими факторами. Необходимость поддержки схематизированных полу-реляционных таблиц и синхронная репликация поддерживается популярностью Megastore [5]. Как минимум 300 приложений внутри Google используют Megastore (несмотря на относительно низкую производительность), так как их моделью данных Megastore управлять проще, нежели моделью данных Bigtable, а также из-за поддержки синхронной репликации между датацентрами. (Bigtable поддерживает только репликацию между датацентрами по модели "согласованность в конечном счете"). Примеры известных приложений Google, которые используют Megastore - это GMail, Picasa, Calendar, Android Market и AppEngine. Необходимость поддержки SQL-подобных запросов в Спаннере было тоже понятна, учитывая популярность Dremel [28] как интерактивого инструмента анализа данных. В конце концов, отсутствие кросс-кортежных транзакций в Bigtable привело к частым жалобам; Percolator [32] был частично написан, чтобы решить эту проблему. Некоторые авторы жаловались, что поддерживать обычный двухфазный коммит слишком дорого из-за проблем производительности, которые он несет [9, 10, 19]. Мы считаем, что лучше предоставить возможность программистам иметь дело с проблемами производительности из-за переиспользования транзакций по мере того, как возникает в этом необходимость, вместо того, чтобы иметь дело и обрабатывать ошибки, возникающие из-за отсутствия транзакций. Использование двухфазного коммита через Paxos облегчает решение проблем доступности.
Модель данных приложения построена поверх отображений ключ значение (расположенных в директориях-корзинах), поддерживаемых реализацией. Приложение создает одну или больше баз данных во вселенной. Каждая база данных может содержать неограниченное количество схематизированных таблиц. Таблицы выглядят как таблицы в реляционной базе данных, с кортежами и колонками, и значениями разных версий. Мы не будем вдаваться в подробности о языке запросов для Спаннера. Он выглядит как SQL с некоторыми расширениями для поддержки полей, имеющими отношение к буфферу протокола.
Модель данных Спаннера не является чисто реляционной, в которой кортежи должны иметь имена. Если говорить точнее, каждая таблица должна содержать отсортированное множество с именами одного или более первичных ключей. Это требование делает Спаннер похожим на хранилище ключ-значение: первичные ключи образуют имя кортежа, и каждая таблица определяет отображение колонки первичного ключа на другие колонки. Кортеж сущестсвует только тогда, когда некоторое значение (даже ели оно равно NULL) используется, потому что оно позволяет приложению контролировать положение данных на основе выбора ключа.
Рис. 4 содержит пример схемы Спаннера для хранения метаданных фотографий для каждого пользователя, для каждого альбома. Язык схем похож на такой язык Megastore, с дополнительными требованиями, что каждая база данных Спаннера должна быть разбита клиентами на одну или более иерархий таблиц. Приложения клиента декларируют иерархии в схемах баз данных через INTERLEAVE IN определения. Таблица на вершине иерархии называется таблицей директории. Каждый кортеж в таблице директории с ключом K, вместе со всеми кортежами в потомках, которые начинаются начинается с K в лексикографическом порядке, образуют директорию. ON DELETE CASCADE гоорит, что удаление кортежа в таблице директории удаляет также ассоциированные кортежи в потомках. Рисунок также иллюстрирует пересекающуюся топологию для примера базы данных: например, Albums (2, 1) представляет собой кортеж из таблицы Albums для user_id 2, album_id 1. Это пересечение таблиц для формирования директории очень важно, т.к. это позволяет клиентам описывать отношение местоположения, которое существует между таблицами, что является необходимым для обеспечения хорошей производительности в распределенной базе данных с шардами. Без неё, Спаннер не обладал бы важной информацией о местоположении.
3 TrueTime
Abstract
Spanner - это распределенная, масштабируемая, мультиверсионная и синхронно-реплицируемая база данных. Это первая система, которая хранит данные распределенно в мировом масштабе и поддерживает распределенные транзакции с внешней консистентностью. Эта статья описывает структуру Spanner его функциональность, предпосылки и рассуждения для принятия каждого решения при разработке дизайна, новое API для синхронизации времени, которое позволяет преодолеть неопределенности во времени. Это API и его имплементация являются критическими для поддержки внешней консистентности и набора мощных функций: неблокирующие чтения, read-only транзакции без блокировок и атомарные изменения схемы в рамках всего Spanner.
1 Введение
Spanner - это масштабируемая, глобально-распределенная база даных, разработанная, построенная и внедренная в Google. На самом высоком уровне абстракции - это база данных, которая шардит данные между множеством наборов конечных автоматов Paxos[21] в датацентрах, расположенных по всему миру. Репликация используется для обеспечения глобальной доступности и географической локализованности; в случае отказа одного из них клиенты автоматически переключаются на другой. Спаннер автоматически решардит данные между машинами по мере того, как меняется объем даных или количество серверов, и автоматически мигрирует данные между машинами (даже между датацентрами) для того, чтобы балансировать нагрузку и в ответ на сбои. Спаннер разработан, для того, чтобы обеспечивать масштабируемость вплоть до миллиона машин между сотнями датацентров и триллионами кортежей данных.
Приложения могут использовать Спаннер благодаря доступности данных даже при природных катаклизмах, т.к. данные реплицируются в пределах и даже между континентами. Нашими первыми клиентами была система F1[35], переработанная версия рекламного бэкенда Google. F1 использует 5 реплик, распределенных в пределах США. Большинство других приложений, вероятно, реплицируют данные между 3-5 датацентрами внутри одной географической области, но с относительно независимыми режимами обработки сбоев. Таким образом, большинство приложений выберут низкую временную задержку (low latency) вместо доступности данных, так как они могут работать при одном или двух сбоях в датацентрах.
Главная цель Спаннера - управление реплицированными данными между датацентрами, но мы также уделили большое внимание дизайну и реализации важной функциональности на основе нашей распределенной инфраструктуры. Несмотря на то, что множество проектов успешно используют Bigtable[9], мы постоянно получаем жалобы от пользователей, что сложно использовать Bigtable для некоторых приложений: таких, которые имеют сложные, изменяющиеся схемы или те, которым необходима строгая консистентность при одновременной репликации в широких пределах. (Подобные жалобы высказывались многими авторами [37].) Множество приложений Google выбрали Megastore [5] из-за ее полу-реляционной модели данных и поддержки синхронной репликации, несмотря на относительно низкую скорость записи. Как результат, Спаннер развивился из похожего на Bigtable версионного хранилища key-value в хронологическую мультиверсионную базу данных. Данные хранятся в схематизированных полу-реляционных таблицах; данные имеют версию, и каждой версии автоматически присваивается время коммита; старые версии данных удаляются сборщиком мусора по конфигурируемым правилам; и приложения могут читать данные со старыми временными метками. Спаннер поддерживает транзакции общего назначения и поддерживает язык запросов на основе SQL.
Как глобально распределенная база данных, Спаннер предоставляет несколько интересных возможностей. Во-первых, конфигурации для репликации данных могут динамически и очень точно контролироваться приложениями. Приложения могут указывать, какие датацентры должны быть использованы для хранения конкретных данных, как далеко от пользователя могут данные находиться (для контроля задержки чтения), как далеко реплики находятся друг от друга (для контроля задержки записи) и как много реплик поддерживается (для контроля устойчивости, доступности данных и скорости чтения). Данные также могут динамически и прозрачно перемещаться системой между датацентрами для балансировки использования ресурсов между датацентрами. Во-вторых, Спаннер имеет 2 особенности, которые сложно реализовать в распределенной базе данных: он обеспечивает внешнюю консистентность [16] чтения и записи, и глобально-консистентные чтения в пределах всей базы данных для заданной временной метки (timestamp). Эти особенности позволяют Спаннеру поддерживать консистентные резервные копии, консистентное выполнение операций MapReduce [12] и атомарные изменения схемы, и все это на глобальном уровне, и даже при одновременном существовании незавершенных транзакций.
Эта функциональность обеспечивается тем фактом, что Спаннер присваивает временные метки коммита каждой транзакции, несмотря на то, что транзакции могут быть распределенными. Временные метки отражают порядок сериализации. В добавок, порядок сериализации удовлетворяет требованию внешней консистентности (или, что то же самое, линериализации [20]): если транзакция T1 завершается перед тем, как начинается другая транзакция T2, тогда временная метка для T1 меньше таковой для T2. Спаннер - это первая система, которая гарантирует это в глобальном масштабе.
Новое TrueTime API и его реализация - это та ключевая часть, которая позволяет реализовать все эти свойства. API напрямую выявляет временную неопределенность и требования, которые накладываются на временные метки, зависят от границ и ограничений реализации. Если неопределенность большая, то Спаннер замедляется, чтобы переждать её. Программное обеспечение для управления кластерами Google предоставляет реализацию TrueTime API. Эта реализация уменьшает временную неопределенность (обычно до 10 миллисекунд) путем использования множества временных источников (GPS и атомные часы).
Секция 2 описывает структуру Спаннера, набор функциональности, и инженерные решения, которые привели к такому дизайну. Секция 3 описывает наше новое TrueTime API и наборски его реализации. Секция 4 описывает, как Спаннер использует TrueTime для реализации внешне-консистентных распределенных транзакций, неблокирующих read-only транзакций и атомарных изменений схемы. В секции 5 - результаты бенчмарков производительности Спаннера и TrueTime и размышления насчет опыта использования F1. Секции 6, 7 и 8 описывают текущую и будущую работу и резюмируют наши заключения.
2 Реализация
Эта секция описывает структуру и размышления, лежащие в основе реализации Спаннера. Затем описывается абстракция директория, которая используется для управления репликацией и местом нахождения реплики, и является единицей перемещения данных. В конце секция описывает нашу модель данных, почему Спаннер выглядит как реляционная база данных, а не key-value хранилище, и как приложения могут контролировать место нахождения данных.
Инсталляция Спаннера называется вселенной. При условии, что Спаннер управляет данными на глобальном уровне, у нас будет только несколько функционирующих вселенных. На данный момент работает вселенная test/playground, вселенная development/production и только-production вселенная.

Рис.1. Организация серверов спаннера
Рисунок 1 показывает сервера во вселенной. Зона имеет своего хозяина зоны и с количеством спансерверов от 100 до нескольких тысяч. Хозяин зоны передает данные спансерверам; последние уже передают их клиентам. По одному на каждую зону, прокси серверы локаций используются клиентами, чтобы определить местонахождение и сам спансервер, который должен отдать данные. Мастерспансервер.
вселенной и драйвер местоположения являются синглтонами. Мастер вселенной - это консоль, которая отображает текущую статусную информацию о всех зонах для интерактивной отладки. Драйвер местоположения автоматически перемещает данные между зонами меньше чем за одну минуту. Драйвер периодически общается со спан серверами, чтобы найти данные, которые необходимо переместить, для того, чтобы удовлетворить изменившимся ограничениям репликации или для балансировки нагрузки. Для экономии места, мы опишем в деталях только
2.1 Спансервер
Эта секция описывает реализацию спансервера, чтобы показать, как репликация и распределенные транзакции были поделены на слои на основе имплементации Bigtable. Набор программных компонент показан на рисунке 2. Внизу, каждый спансервер ответственен за структуры данных, называемые таблетами, количество которых находится в пределах от 100 до 1000 экземпляров. Таблет похож на абстракцию таблет в Bigtable, и реализует множество следующих соответствий:
(ключ: string, временная метка: int64) -> string
В отличие от Bigtable, Спаннер присваивает данным временную метку, которая делает Спаннер скорее мультиверсионной базой данных, нежели хранилищем key-value. Состояние таблета хранится в наборе файлов, похожих на B-дерево и в логе, все это в распределенной файловой системе, называемой Колоссом (последователем Google File System [15]).
Для поддержки репликации, каждый спансервер реализует одиночный конечный автомат Paxos поверх каждого таблета. (Ранние версии Спаннера поддерживали множество конечных автоматов Paxos для одного таблета, что давало возможность более гибко настраивать репликацию. Сложность этого дизайна заставила нас отказаться от этого.) Каждый конечный автомат хранит свои метаданные и логгирует их в соответствующем таблете. Наша реализация Paxos поддерживает долгоживущих лидеров со сроком жизни 10 секунд. Текущая реализация Спаннера сохраняет каждую запись в лог дважды: в лог таблета и в лог Paxos. Это - недостаток проектирования и он, вероятно, будет скоро исправлен. Наша реализация Paxos поддерживает конвейерные операции для того, чтобы улучшить пропускную способность Spanner при наличии задержек WAN: но транзакции записи, осуществляемые Paxos проходят в корректной последовательности (факт, от которого мы будем зависеть в Секции 4).
Конечный автомат Paxos используется для реализации постоянно реплицируемого множества соответствий. Множество key-value каждой реплики хранится в соответствующем таблете. Операции записи должны инициировать протокол Paxos на стороне лидера; чтение множества производятся напрямую из нижележащего таблета любой реплики, таблет выбирается самый актуальный. Набор реплик является группой Paxos.
У каждой реплики, которая является лидером, каждый спансервер реализует таблицу блокировок для управления параллелизмом. Таблица блокировок содержит состояние для двухфазной блокировки: она сопоставляет каждому интервалу ключей свое состояние блокировки. (Заметьте, что наличие долгоживущих лидеров Paxos является критическим фактором для эффективного управления таблицами блокировок). Как в Bigtable так и Спаннере, мы разрабатывали дизайн для долгоживущих транзакций (например, для создания отчетов, что могло занять несколько минут), которые имеют низкую производительность при оптимистичном контроле параллелизма (optimistic concurrency control) в присутствии конфликтов. Операции, которые требуют синхронизации, такие как транзакционные чтения запрашивают блокировку в таблице блокировок; другие - игнорируют таблицу.
В каждой реплике, которая является лидером, каждый спансервер использует транзакционный менеджер для поддержки распределенных транзакций. Транзакционный менеджер используется для реализации лидера-участника; другие реплики в группе называются ведомыми участниками. Если транзакция включает в себя только одну Paxos группу (также как и в случае большинства транзакций), она может не использовать менеджер транзакций, так как таблица блокировок и Paxos вместе обеспечивают транзакционность. Если в транзакцию вовлечены более чем одна группа Paxos, такие лидеры групп координируются и выполняют 2-х фазный коммит. Одна из групп-участников выбирается в качестве координатора: лидер участник этой группы будет называться координационным лидером, и ведомые будут соответственно называться координационными ведомыми. Состояние транзакционного менеджера хранится в нижележащих Paxos группах (и таким образом, реплицируется).
2.2 Директории и местоположение
На вершине всего набора отображений ключ-значение, реализация Спаннера поддерживает абстракцию корзин, называемую директорией, что есть непрерывный набор ключей, которые имеют общий префикс. (Понятие "директория" является исторической случайностью; "корзина" была бы более подходящим названием). Мы поясним источник этого префикса в секции 2.3. Поддержка директорий позволяет приложениям контролировать нахождение данных с помощью аккуратного выбора ключа.
Директория - это единица размещения данных. Все данные в директории имеют одну и ту же конфигурацию для репликации. Когда единица данных перемещаются между группами Paxos, то она перемещается директория за директорией, как это показано на рис. 3. Спаннер может перемещать директорию для планирования нагрузки из группы Paxos; чтобы расположить директории используемые вместе, в группу, которая ближе к своим пользователям. Директории могут быть перемещены во время выполнения клиентских операций. Можно ожидать, что 50 Мб директория может быть перемещена за несколько секунд.
Факт, что группа Paxaos может содержать несколько директорий предполагает, что таблет Спаннера отличается от таблета в Bigtable: первый не обязательно будет единственным лексикографически непрерывным разбиением в памяти. Наоборот - таблет в Спаннер является контейнером, который может выключать в себя множественные разбиения свободного пространства. Мы пришли к такому решению для того, чтобы сделать возможной систематизацию множества директорий, часто используемых вместе.
Movedir - это фоновая задача, которая используется для перемещения директорий между группами Paxos [14]. Movedir также используется для добавления и удаления реплик в группах Paxos [25], т.к. Спаннер еще не поддерживает изменения конфигурации внутри самого Paxos. Movedir реализован не как одна единственная транзакция, для того, чтобы избежать блокирования параллельно выполняющихся процессов чтения и записи во время перемещения. Вместо этого, movedir отмечает факт, что он начинает перемещать данные и перемещает данные в фоне. Когда он переместил все, за исключением последней маленькой части данных, он использует транзакцию, чтобы переместить эту малую часть атомарно и обновить метаданные для двух групп Paxos.
Директория также является минимальной единицей, чьи свойства репликации в зависимости от местоположения могут быть установлены приложением. Дизайн нашего языка спецификации местоположения позволяет разделить ответственность для управления конфигурациями репликации. Администраторы контролируют два измерения: количество и типы реплик и их географическое положение. Они создают меню именованных опций в этих двух измерениях (напр. Северная Америка, реплицируется по 5 путям с одним свидетелем). С помощью назначения комбинации этих параметров каждой базе данных приложение контролирует процесс репликации этих данных. Например, приложение может хранить данные каждого конечного пользователя в его собственной директории, что позволит данным пользователя A иметь 3 реплики в Европе, а данным пользователя B иметь 5 реплик в Северной Америке.
Для того, чтобы это было более понятно, мы всё сильно упростили. В действительности, Спаннер будет шардить директории на множество фрагментов, если директория станет слишком большой. Фрагменты могут быть отданы из разных групп Paxos (и таким образом, находящимися на разных серверах). Movedir на самом деле перемещает между группами фрагменты, а не целые директории.
2.3 Модель данных
Спаннер предоставляет приложениям следующий набор функций: модель данных, основанная на схематизированных пол-реляционных таблицах, язык запросов и транзакции общего назначения. Движение по направлению к поддержке этих функций поддерживалось многими факторами. Необходимость поддержки схематизированных полу-реляционных таблиц и синхронная репликация поддерживается популярностью Megastore [5]. Как минимум 300 приложений внутри Google используют Megastore (несмотря на относительно низкую производительность), так как их моделью данных Megastore управлять проще, нежели моделью данных Bigtable, а также из-за поддержки синхронной репликации между датацентрами. (Bigtable поддерживает только репликацию между датацентрами по модели "согласованность в конечном счете"). Примеры известных приложений Google, которые используют Megastore - это GMail, Picasa, Calendar, Android Market и AppEngine. Необходимость поддержки SQL-подобных запросов в Спаннере было тоже понятна, учитывая популярность Dremel [28] как интерактивого инструмента анализа данных. В конце концов, отсутствие кросс-кортежных транзакций в Bigtable привело к частым жалобам; Percolator [32] был частично написан, чтобы решить эту проблему. Некоторые авторы жаловались, что поддерживать обычный двухфазный коммит слишком дорого из-за проблем производительности, которые он несет [9, 10, 19]. Мы считаем, что лучше предоставить возможность программистам иметь дело с проблемами производительности из-за переиспользования транзакций по мере того, как возникает в этом необходимость, вместо того, чтобы иметь дело и обрабатывать ошибки, возникающие из-за отсутствия транзакций. Использование двухфазного коммита через Paxos облегчает решение проблем доступности.
Модель данных приложения построена поверх отображений ключ значение (расположенных в директориях-корзинах), поддерживаемых реализацией. Приложение создает одну или больше баз данных во вселенной. Каждая база данных может содержать неограниченное количество схематизированных таблиц. Таблицы выглядят как таблицы в реляционной базе данных, с кортежами и колонками, и значениями разных версий. Мы не будем вдаваться в подробности о языке запросов для Спаннера. Он выглядит как SQL с некоторыми расширениями для поддержки полей, имеющими отношение к буфферу протокола.
Модель данных Спаннера не является чисто реляционной, в которой кортежи должны иметь имена. Если говорить точнее, каждая таблица должна содержать отсортированное множество с именами одного или более первичных ключей. Это требование делает Спаннер похожим на хранилище ключ-значение: первичные ключи образуют имя кортежа, и каждая таблица определяет отображение колонки первичного ключа на другие колонки. Кортеж сущестсвует только тогда, когда некоторое значение (даже ели оно равно NULL) используется, потому что оно позволяет приложению контролировать положение данных на основе выбора ключа.
Рис. 4 содержит пример схемы Спаннера для хранения метаданных фотографий для каждого пользователя, для каждого альбома. Язык схем похож на такой язык Megastore, с дополнительными требованиями, что каждая база данных Спаннера должна быть разбита клиентами на одну или более иерархий таблиц. Приложения клиента декларируют иерархии в схемах баз данных через INTERLEAVE IN определения. Таблица на вершине иерархии называется таблицей директории. Каждый кортеж в таблице директории с ключом K, вместе со всеми кортежами в потомках, которые начинаются начинается с K в лексикографическом порядке, образуют директорию. ON DELETE CASCADE гоорит, что удаление кортежа в таблице директории удаляет также ассоциированные кортежи в потомках. Рисунок также иллюстрирует пересекающуюся топологию для примера базы данных: например, Albums (2, 1) представляет собой кортеж из таблицы Albums для user_id 2, album_id 1. Это пересечение таблиц для формирования директории очень важно, т.к. это позволяет клиентам описывать отношение местоположения, которое существует между таблицами, что является необходимым для обеспечения хорошей производительности в распределенной базе данных с шардами. Без неё, Спаннер не обладал бы важной информацией о местоположении.
3 TrueTime


Comments